Why AI Pipelines Fail at Scale — and what to do about it
Most AI pipeline failures are not model failures. The model is doing exactly what it was trained to do. The failure is governance — what happens to the decisions the model can't confidently make.
Here is the pattern I see repeatedly in scaling B2B companies: automation volume increases, edge cases multiply, and the humans responsible for handling exceptions start routing around the system rather than through it. The pipeline remains nominally active. Trust quietly collapses. The sales team stops believing what the CRM tells them. RevOps credibility declines.
By the time this is visible as a revenue problem, it has been an operational problem for months.
The failure isn't model performance. It's that every override disappears into a Slack thread with no reason code, no feedback loop, and no path back into the model.
The fix is not a better model. It is designing exception handling as a first-class system concern — treating override telemetry not as a cleanup task, but as the primary mechanism through which the system gets smarter over time.
The Architecture
Below is the framework I use to model how AI-enabled revenue pipelines behave under scale. It separates core decision logic from override governance and surfaces exception telemetry as a signal — not an afterthought.
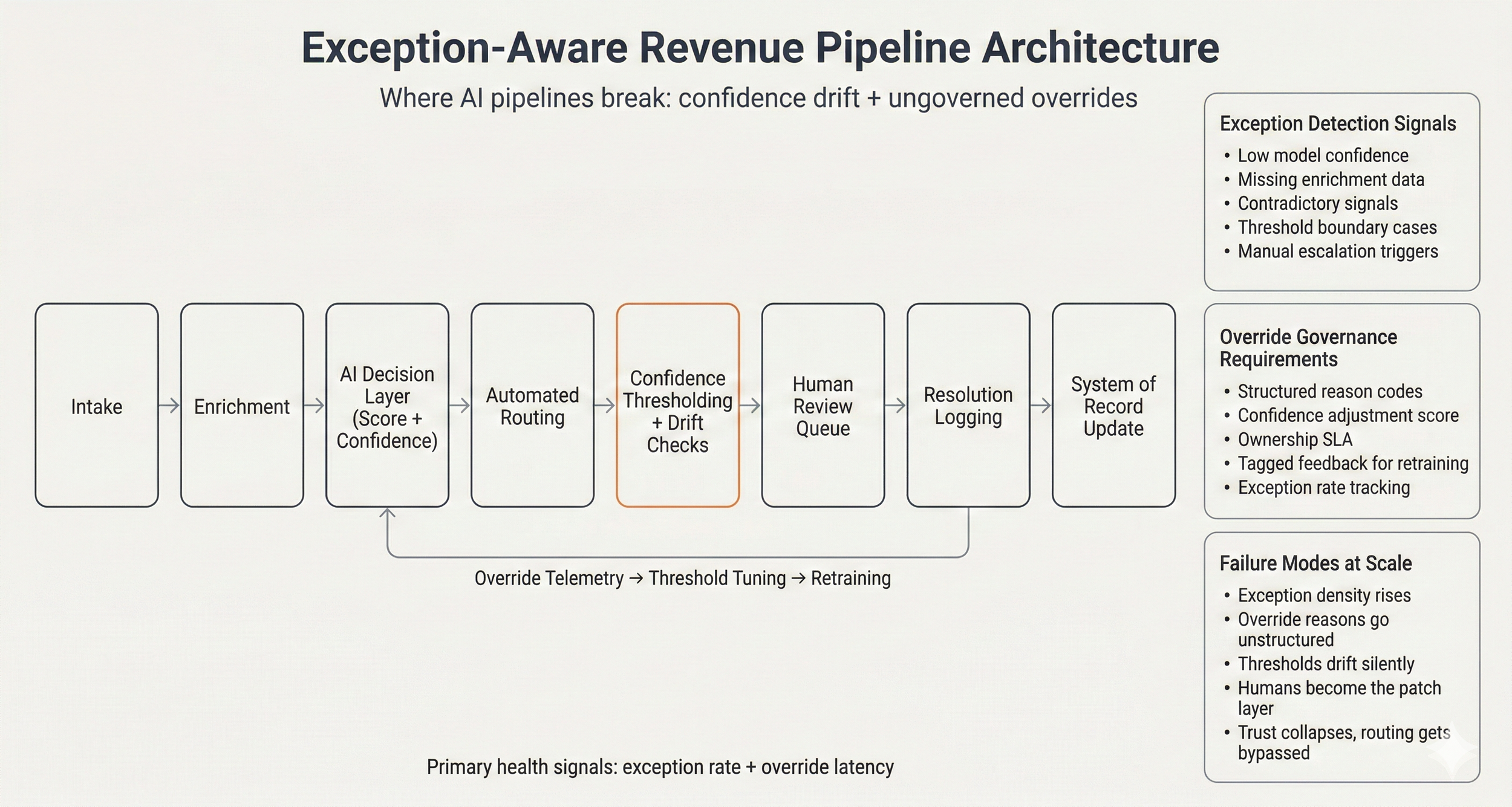
Primary health signals: exception rate + override latency. Where pipelines break: confidence drift + ungoverned overrides.
The pipeline works as follows. Raw demand enters through intake — form fills, demo requests, event triggers, partner referrals. An enrichment layer augments that signal with third-party data and historical activity, reducing uncertainty before the AI touches it. The decision layer outputs two things: a score and a confidence metric. Both matter. The score tells you what to do. The confidence tells you how much to trust it.
What happens next is where most implementations break down.
The Confidence Layer
Automated routing works well when the model is confident. The problems accumulate in the middle — cases that score near threshold boundaries, records with missing enrichment data, signals that contradict each other. These cases need a human. The question is whether that human intervention is structured or unstructured.
Unstructured override is the default. A rep flags a lead, a manager reviews it in Slack, the decision gets made, and the reasoning evaporates. No reason code. No confidence adjustment. No signal that could be used to retrain the model or tune the threshold. The system doesn't get smarter. It just keeps producing the same borderline cases.
Structured override is the alternative. Every human review routes through a defined queue with ownership and SLA. Every resolution captures a reason code, a confidence adjustment, and contextual tags. That data flows back into threshold tuning and, eventually, model retraining. Override events stop being patches and become training data.
The Five Failure Modes
These are not hypothetical. They are the states I find most often when I map a client's decision flow for the first time.
Exception density rises without visibility As volume scales, edge cases and borderline classifications increase proportionally. Without a defined exception rate metric, the signal is invisible until it becomes a revenue problem.
Override reasons go unstructured Free-text explanations in Slack threads and email chains cannot be aggregated. You cannot tune thresholds or retrain a model on reasoning you cannot query.
Thresholds drift silently Model performance degrades over time through distribution shift, segment bias, and rising false positives. Without drift monitoring, the system appears stable while routing quality quietly declines.
Humans become the patch layer Automation remains nominally active but is increasingly bypassed. The team learns to work around the system rather than through it. Manual load rises while the model receives no corrective signal.
Trust collapses Sales teams stop trusting the scores. RevOps loses credibility. Routing gets bypassed. The pipeline becomes a formality, not a system. Recovery at this stage is expensive.
What Healthy Looks Like
A well-governed pipeline has two primary health signals. Everything else is a lag indicator.
Exception Rate — the percentage of decisions requiring human intervention. Measures automation stress before it manifests as revenue impact.
Override Latency — average time from exception trigger to resolution. Measures whether the human review layer is functioning or becoming a bottleneck.
These two metrics, tracked together, give you an early warning system. Exception rate rising signals model stress or threshold drift. Override latency rising signals queue ownership breakdown. Either pattern, caught early, is correctable. Caught late, it is a rebuild.
The override governance layer has four requirements: structured reason codes that can be aggregated, a confidence adjustment score for each review, defined ownership with SLA accountability, and feedback tagging that makes override events programmatically accessible for retraining. None of these are technically complex. All of them require deliberate design upfront.
RevOps maturity is not measured by automation volume. It is measured by how well override telemetry is governed and reintegrated into the decision layer. The companies that compound on their AI investments are the ones that treat exceptions as signal, not noise.
Is your pipeline self-correcting or self-degrading?
I run a structured diagnostic that maps your current decision flow, identifies where exceptions disappear, and designs the governance layer your automation needs to scale.